面临的问题:传统ETL流程的挑战
最近在尝试做一些行业垂直应用。
比如在电子元器件行业,我的想法是给采购人员提供一个询价助手,其中功能之一就是获取元器件电商平台的公开价格。
以往的数据ETL过程,往往需要获取全量数据,清洗整理后入库存起来。这样耗费大量力气不说,数据及时性也无法保证。
我的思路是,摒弃传统的爬取→清洗→展示流程,改为在接到采购指令后,实时从指定电商平台获取所需元器件型号的价格和库存信息。大致流程如下:
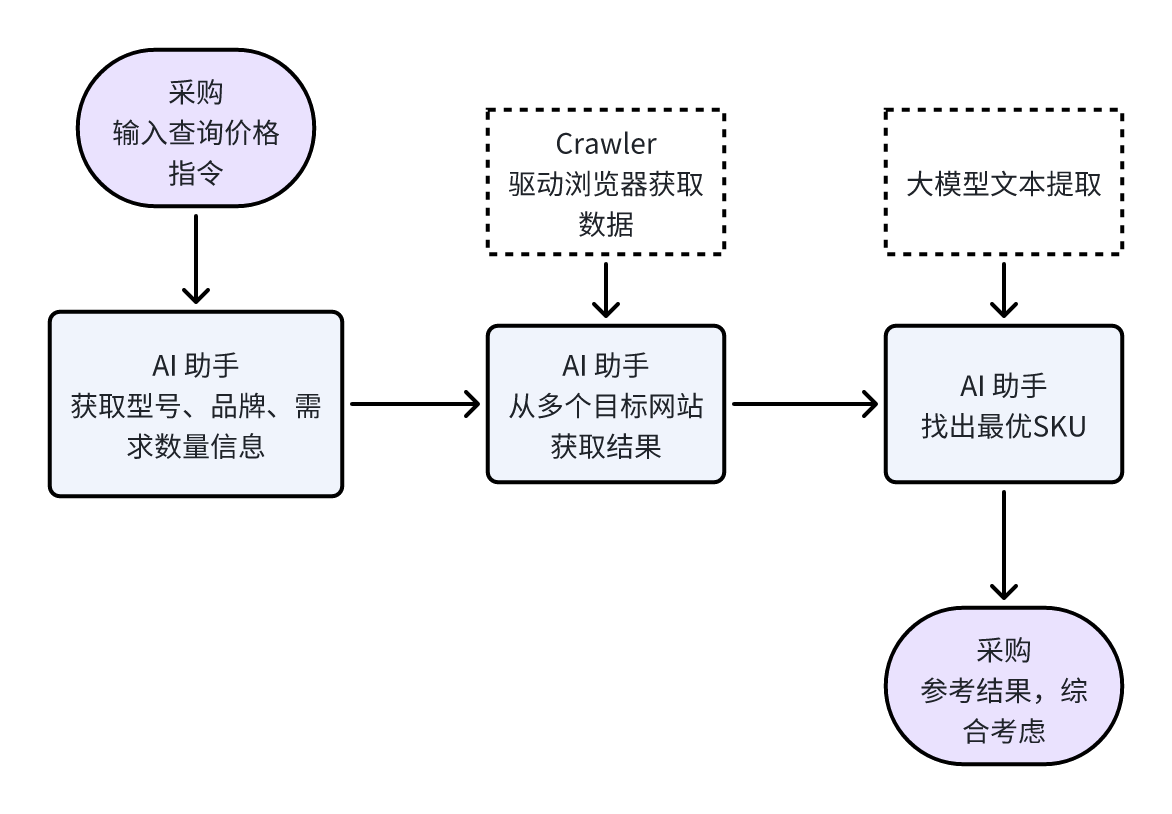
我的理解是:
- 而当前阶段的大模型,我认为其最擅长的是基于已有知识库的分析、总结和提炼。
- 至于速度问题,随着大模型能处理的 token 越来越多,并结合缓存技术,能很好地提高响应速度。
所以,期望采用基于大模型的 AI 方案,能解决数据更新不及时、全量数据不全的问题。
第一阶段,我先手动验证流程的可行性,下面是将会用到的两个工具:
- GPT Crawler(一个基于Web 自动化测试框架的简易爬虫)
- 文心一言
如何解决
准备环境
该项目要想在本地使用,需先安装两个工具:
- 一个是从github 下载代码包到本地,需要用到git
- 一个是该项目依赖于node.js,运行该项目使用npm命令,需要用到node.js
以上两个软件,都是直接下载,安装即可。我的是Windows系统,git选用的Windows版本,node.js选用“Recommended For Most Users”这个版本,一般会比最新版本更具兼容性。
下载 gpt-crawler
将代码包下载到本地,你可以先进入你要存放的文件目录。比如我就放在D盘下。
- 在cmd进入D盘
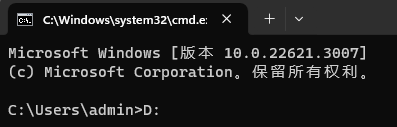
- 从github上下载gpt-crawler代码包
git clone https://github.com/builderio/gpt-crawler
安装依赖
所谓依赖包,可以理解为 gpt-Crawler 要正常跑起来的一些前提条件。
- 需要注意,先进入package.json所在目录执行依赖安装。目前package.json在D盘的git-crawler文件夹下:
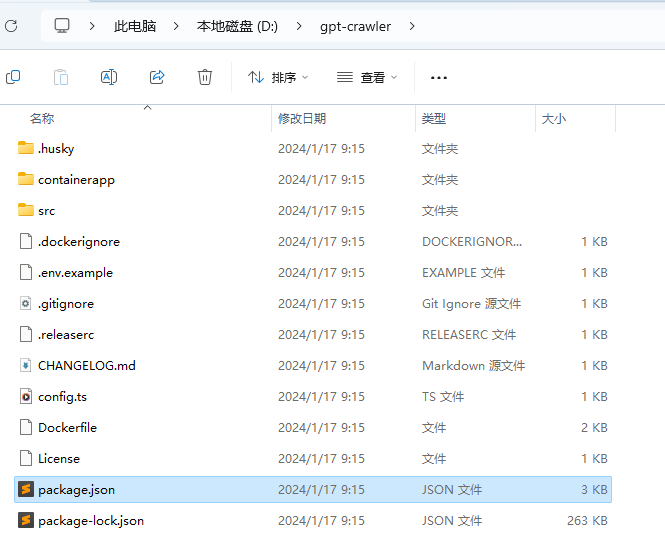
- 输入以下终端命令,进入该文件夹下
cd D:/gpt-crawler
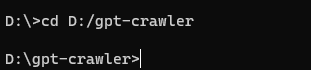
- 执行安装依赖包的操作
npm i
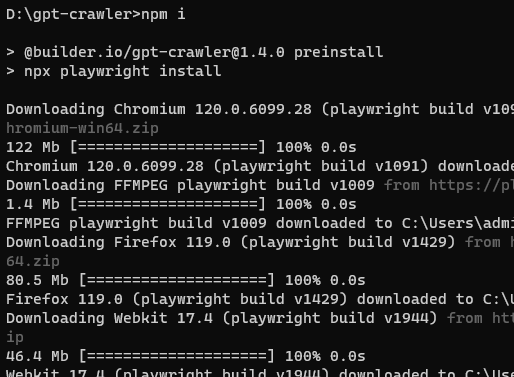
这里面最重要的 Playwright 这个包。可以帮助我们自动化网页操作,即使网页内容是通过动态加载的,也能成功获取。
等待一段时间,安装好所有依赖包后,接下来就可以正式开始获取网站数据了。
配置抓取目标
打开gpt-crawler下的config.ts文件,用Windows自带的记事本就可以打开,然后配置相关参数。
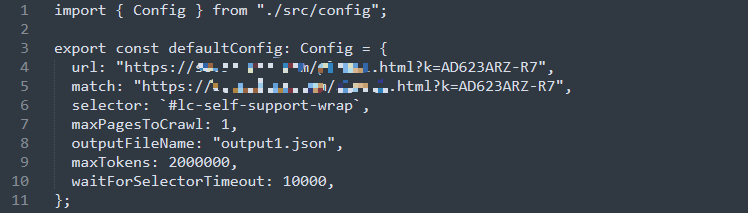
GPT Crawler 需要你告诉他网页中你感兴趣的部分,然后GPT Crawler去“复制”它。具体来说,主要配置这3个参数:
Url:你需要抓取网页的地址。
Match:如果你想抓取一系列网页,这可以配置这个,可参见[1]里的相关描述。
selector:告诉GPT Crawler你想要提取哪些文本信息。
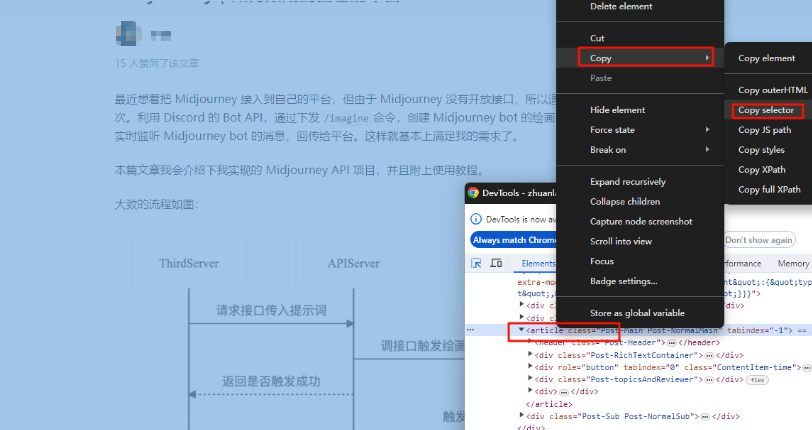
如何获取呢,举个例子,比如你想抓取知乎这篇文章全文,则可以选中一段内容,右键→检查(或F12),然后找到整篇文章 (根据网页的高亮提示,找到对应的html元素):
爬取数据
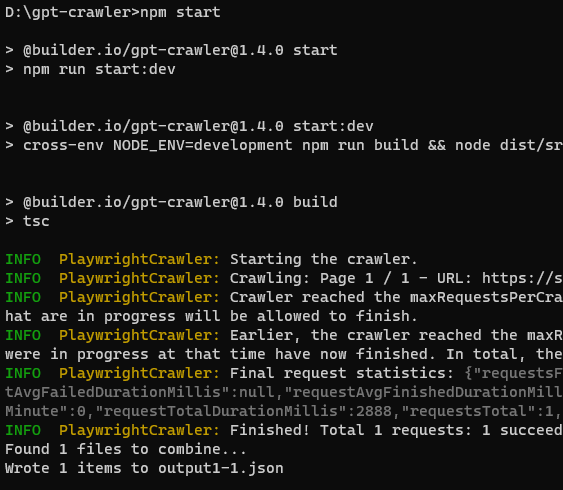
好了,万事俱备,现在我们启动程序,开始抓取内容。在cmd终端,同样在gpt-crawler目录下,输入以下命令:
npm start
文心一言提取目标数据
GPT Crawler抓取到数据,并不能直接使用,还需要进一步提取出价格和库存信息。为了继续不写一行代码,我们使用大模型的文本分析能力来处理。这里选择文心一言来尝试,具体如下:

可以看到,其准确的给出的我所需要的价格和库存信息,那么至此,不写一行代码,手动抓取价格的任务算完成了。(cmd 终端里的命令不能算代码哈)
更进一步
先申明,我只是个产品,并不太懂技术这块,以下只是我的进一步设想:
- 如果将GPT Crawler的config.ts配置项目,经过包装后放到前台,接收采购的询价指令,查询多个指定电商平台的价格库存信息
- 如果将GPT Crawler获取到的结果数据,通过api方式调用大模型返回最终的价格和库存信息
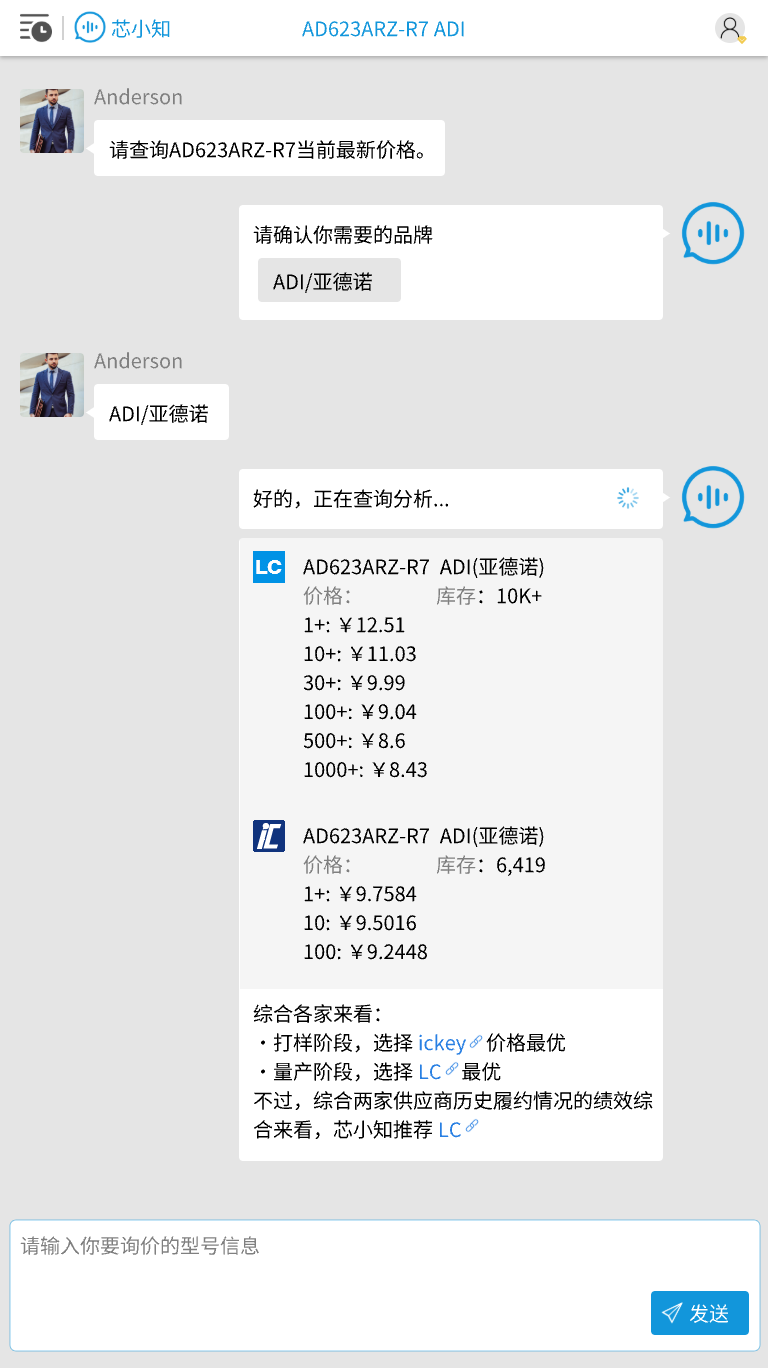
那么,这个采购询价助手的电商平台实时价格查询功能的粗糙版本就算完成了:
参考文档:
[1] GPT Crawler,一个有意思的开源项目 https://zhuanlan.zhihu.com/p/667664219
[2]GPT Crawler Github 仓库 https://github.com/BuilderIO/gpt-crawler